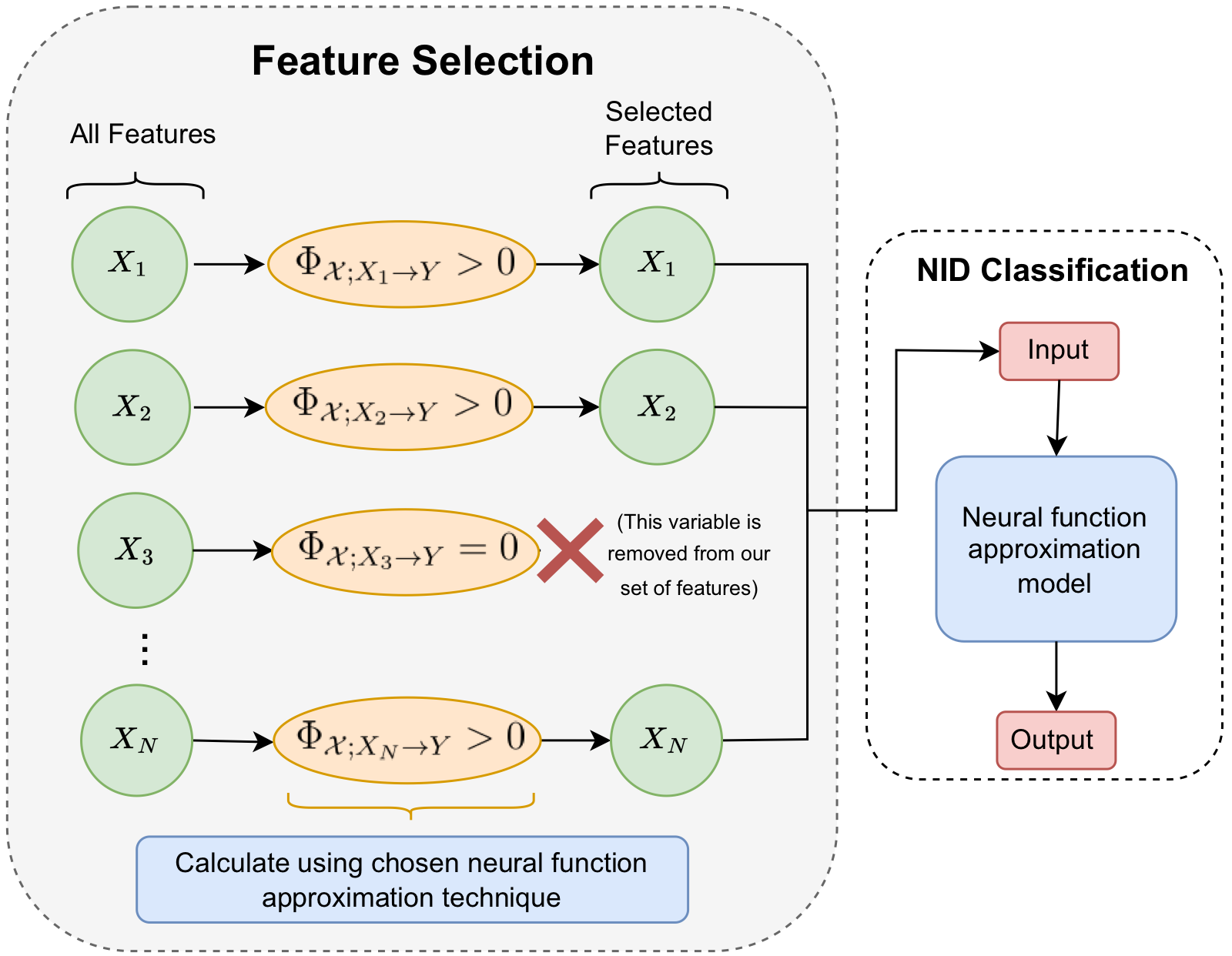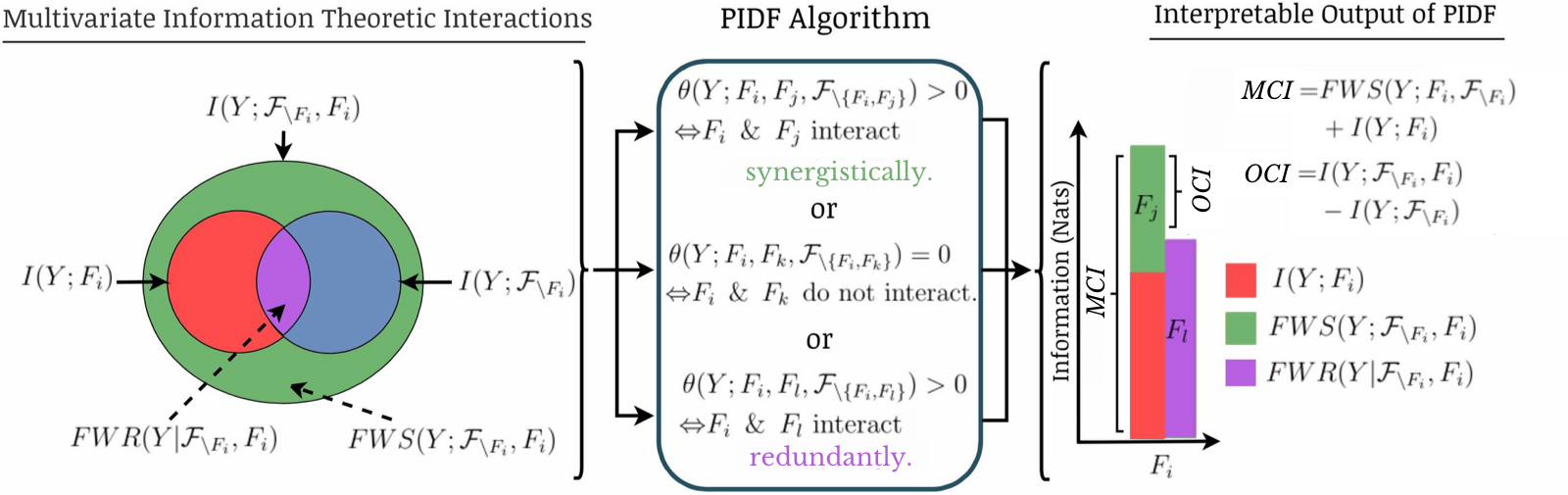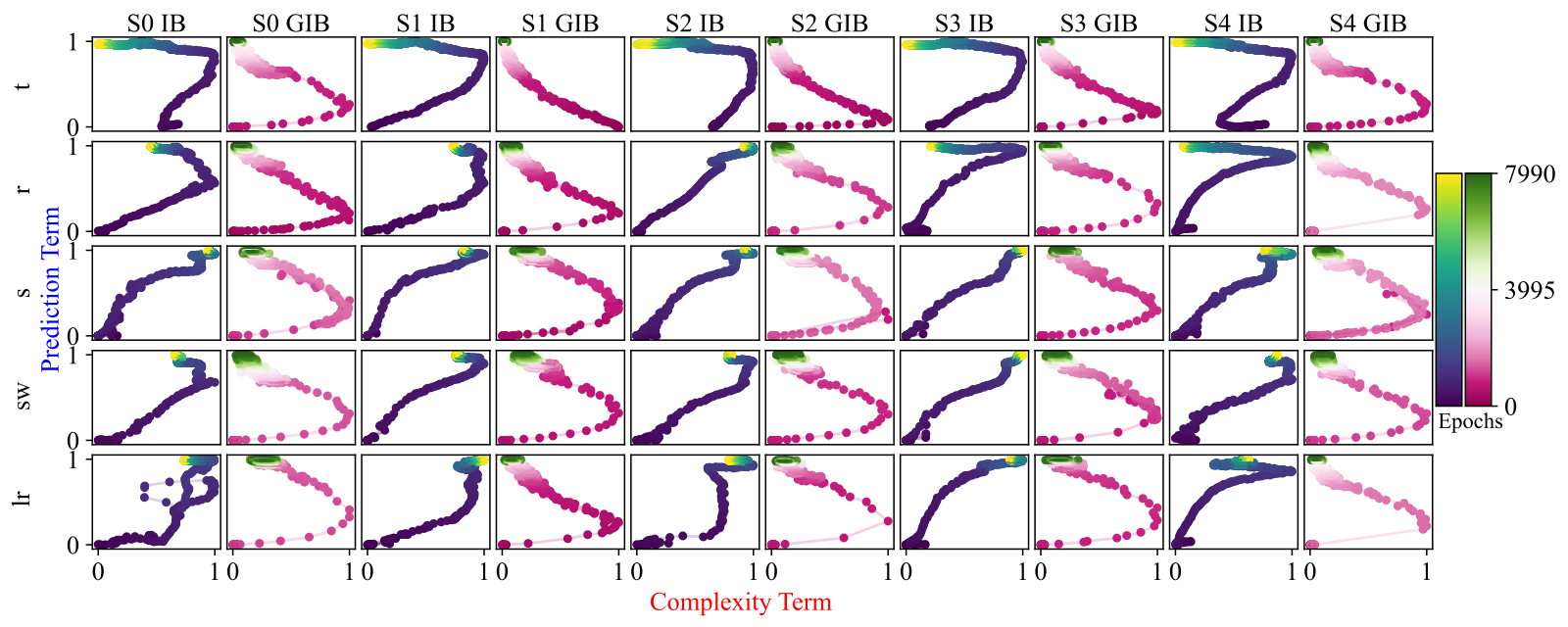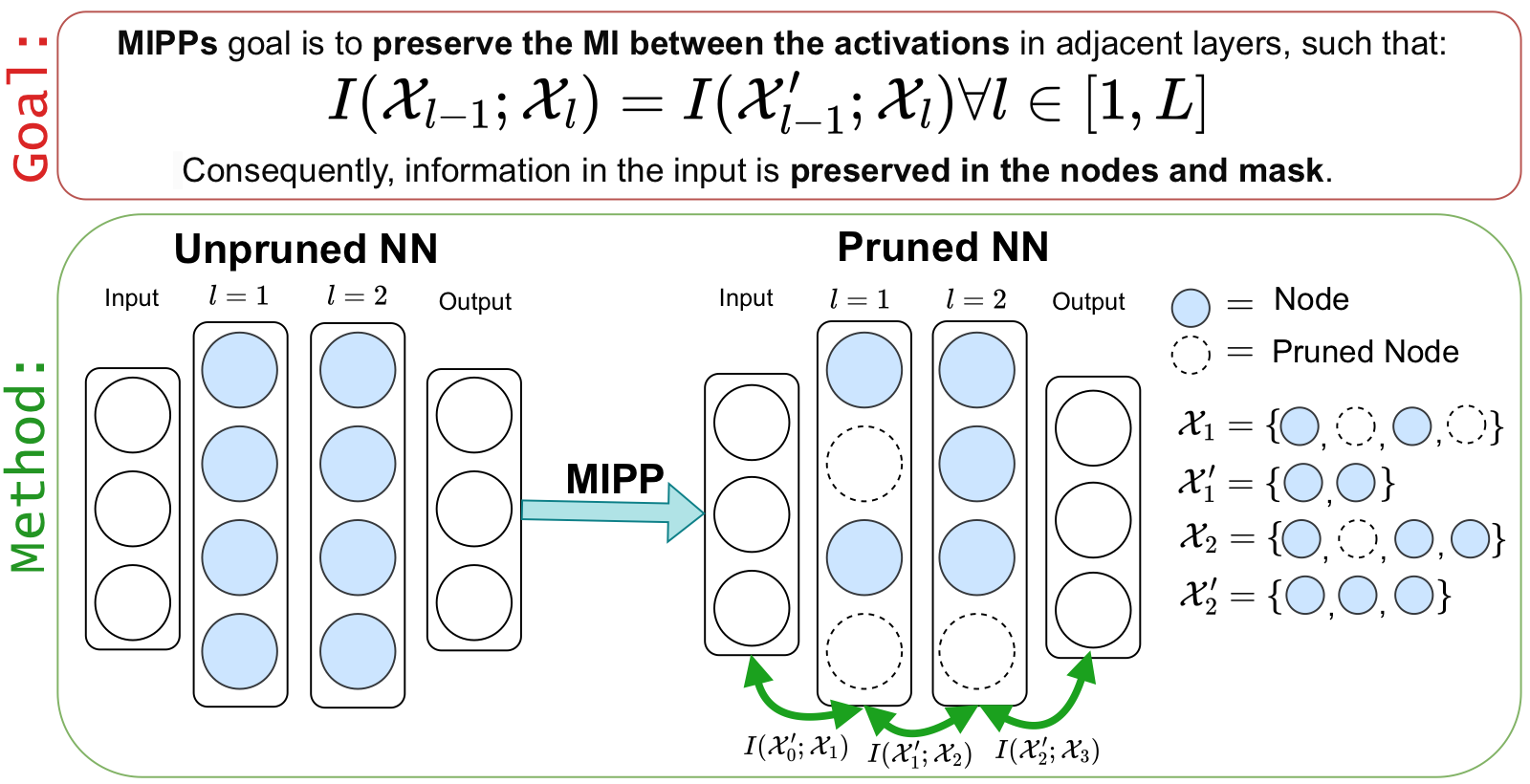
Hide and Seek in Embedding Space: Geometry-based Steganography and Detection in Large Language Models
ICML 2026
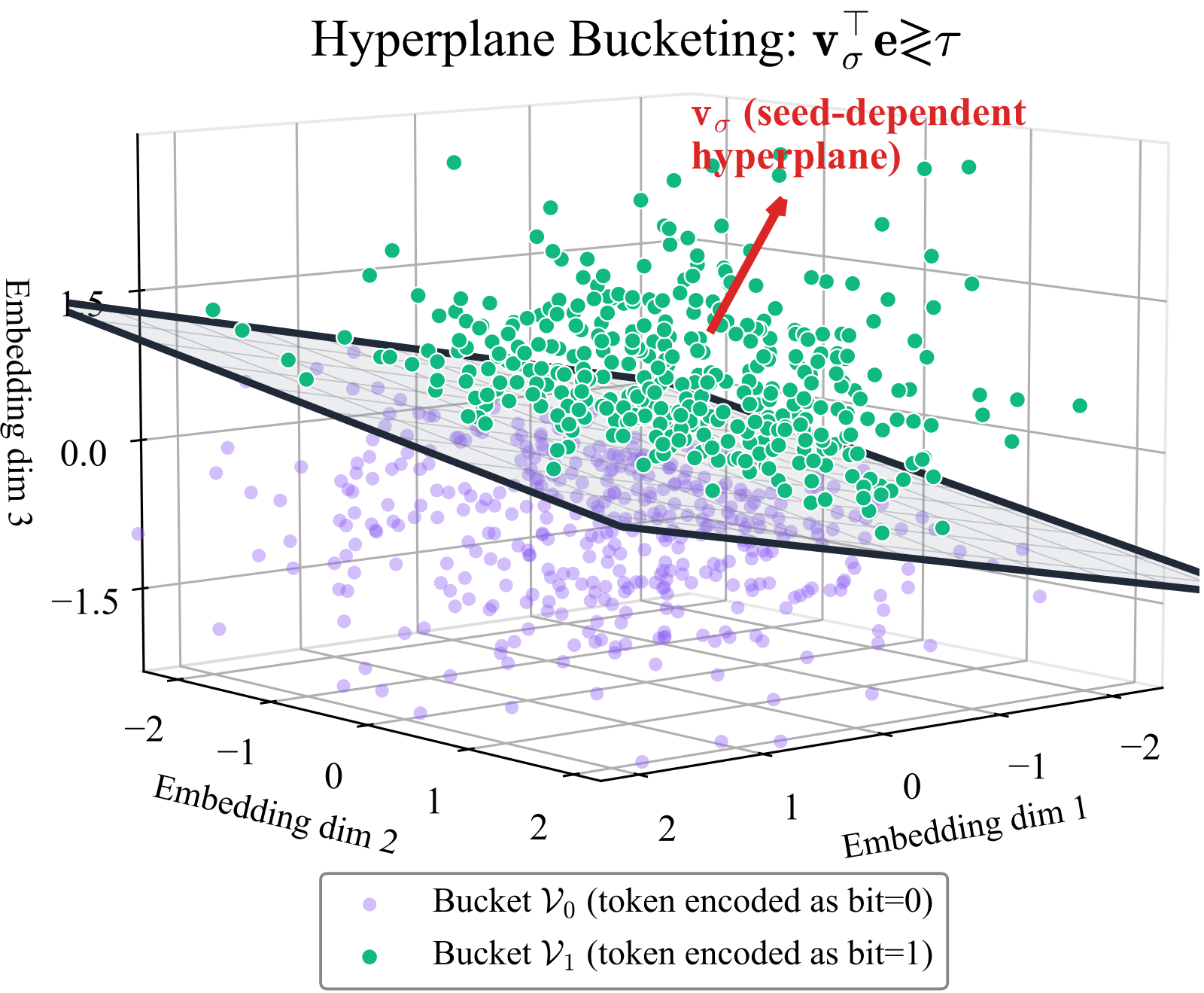
A geometry-based steganography scheme that hides secrets in fine-tuned LLM outputs via embedding-space hyperplanes, together with a linear-probe detector that exposes it more reliably than traditional steganalysis.